



In Detect Person Names in Text: Part 1 (Results), we benchmarked our new named entity recognizer (NER) against popular open source alternatives, such as Stanford NER, Stanza and SpaCy. Today we dig a little deeper into the NER architecture and technical details.
Key Takeaways
- Detecting person names in text at scale relies on advanced Named Entity Recognition (NER) models, often powered by transformer-based architectures rather than simple rule-based systems.
- Modern production systems combine machine learning and rule-based logic to improve precision, reduce false positives, and handle edge cases in real-world PII detection workflows.
- Model performance is typically measured using precision, recall, and F1 score, making evaluation a critical step when deploying name detection systems in production environments.
- Multilingual and domain-specific adaptation is essential for accuracy, especially when processing global datasets or industry-specific documents with unique naming patterns.
- Efficient person name detection requires optimized pipelines for speed and scalability, including batching, preprocessing, and model inference optimization.
- Hybrid approaches improve reliability in enterprise PII detection systems, balancing flexibility (ML models) with control (rules and heuristics) for compliance-driven use cases.
- High-quality name detection directly supports data privacy and compliance initiatives, enabling better protection of sensitive information in line with regulations like GDPR and other global standards.
A Brief Review of NER
First, recall our main NER objectives. In short, we require our NER to be practical, rather than just accurate on some clean academic dataset:
- Useful in arbitrary document contexts: This is where most off-the-shelf solutions fail, having a narrow domain of application and failing horribly on out-of-domain (AKA real-world) documents. PII Tools must process a broad range of documents, so NER must not fail on "weird" input.
- Multi-language support: Aim for English, Spanish, German, and Portuguese (Brazil) to start with, but make adding new languages easy.
- Accurate: obvious, no one wants to see wrong results.
- Fast on a CPU: PII Tools must process terabytes of data quickly. Specialized GPU hardware is only used during model training, not during model usage (inference).
- Control of model behavior: Every machine learning system makes mistakes, so at least we want direct control over what kind of mistakes it makes. Not all NER errors are created equal; from the user perspective, some are more embarrassing / costlier than others. We also require a robust way to implement and evaluate updates.
How NOT to build a practical NER
The most effortless way to do NER is to grab an existing pre-trained model, and just use that.
If you've ever tried this, you probably found out quickly that this leads nowhere in practice – the models are too brittle, trained on artificial datasets, with narrow domain-specific preprocessing. They fail (worse: fail unpredictably) when applied to real documents in the wild. This approach is useful mostly for leaderboards and academic articles, where people compare the accuracy of different model architectures on a fixed, static dataset (the so-called state-of-the-art or SOTA dataset).
The second popular way to create a NER is to fetch an already prepared model and tune it on your own data. For the NER task of "I give you text, you give me the positions of all person names within the text", training data is scarce and usually not very diverse. The state-of-the-art models are transformers, a special kind of neural network, which are quite slow and memory hungry (although there is active research to make them faster). Manually labelling huge amounts of text is costly too. So this was not the way for us.
Bootstrapping a NER
Our approach is incremental, bootstrapping from existing datasets and open source tools:
- Prepare a large and diverse unlabeled dataset automatically.
- Annotate the corpus automatically using multiple fast but low-accuracy open source tools.
- Correct annotation errors semi-automatically.
- Train a stand-alone NER pipeline using Tensorflow with convolutional neural networks.
- Optimize NER for production: squeeze model size and performance with Tensorflow Lite, DAWG, mmap, and other tricks.
Let's go over these steps one by one.
Diverse dataset
Garbage-in, garbage-out. The quality of training data is essential, so we spent a lot of effort here. We built a powerful pipeline, combining automated and manual labelling in a feedback loop:

PII Tools pipeline to build an annotated NER dataset.
We use various text sources, to include the kinds of contexts one could find person names in:
- OSCAR corpus: a large set of crawled text from web pages by Common Crawl.
- Reddit: forum comments from reddit.com.
- Gutenberg: books from the Gutenberg Project.
- Enron emails: published corporate emails.
- Wiki Leaks : documents and articles on various topics.
- Extensive gazetteers of person names and cities. Cities (home addresses) and person names appear in similar contexts, with similar formatting, and are a common source of confusion for NER models in general. So paying close attention to cities and addresses pays off in name detection.
- In-house dataset of documents, part of PII Tools, proprietary. Includes Excel spreadsheets, PDFs (incl. for OCR), Word and various corner-case formats and contexts.
After resampling and deduplication, we filtered down to texts in only those languages we care about: English, German, Portuguese, and Spanish to begin with.
Aside: Language identification
One might think that language identification in text is an easy problem. But just like with NER, existing tools have painful issues like slow speed or low accuracy across different languages. See also Radim's paper on Language Identification.
After internal testing and evaluation of available solutions, we ended up creating a hybrid of a simple & fast n-gram language detector based on CLD2 and fastText language identification. This is what we used for the "corpus language filtering" mentioned above.
End of aside
Semi-supervised annotation
The next part of the dataset building process is to automatically annotate the raw corpora above. That is, mark the position of the person's name in each corpus document. We use existing NER engines for this initial bootstrap step. This technique is sometimes called "weak labeling".
Basically, Stanford NER and spaCy were the only viable options here since the dataset was quite big (see NER performance charts). Even for these two relatively fast libraries, it took several days to annotate the entire corpus.
So now we had a large amount of text annotated with person names. It contained a lot of mistakes, though – neither Stanford NER's nor spaCy's out-of-the-box models work very well outside of their trained domain. So another step was to clean the data, remove the obvious (classes of) errors.
That was a bit of manual work; we had to go through a subset of NER results, identify the most common patterns of errors, write transformation rules, and re-annotate. For instance, no, “Ben & Jerry” is not a person, and “Stephen Crowd carpenter” is a person's name with occupation slapped at the end. Those and other similar mistakes are easily removed in bulk once we get to know them, using our superior "biological neural network," AKA brain.
We use this dataset preparation strategy for English, Spanish, and German. For Portuguese (for Brazil's LGPD), we had to resort to a slightly different approach since we found no existing NER with good enough performance. So instead, we translated Portuguese texts with the Lite-T5 translator to English, recognized named entities with Stanford NER and spaCy, and then simply remapped them back into the original text. The automatic translation took a few weeks but required no manual work.
In the end, we built 10 GB (20M training samples) of annotated text, with surprisingly high quality considering it was produced mostly automatically.
Neural network model
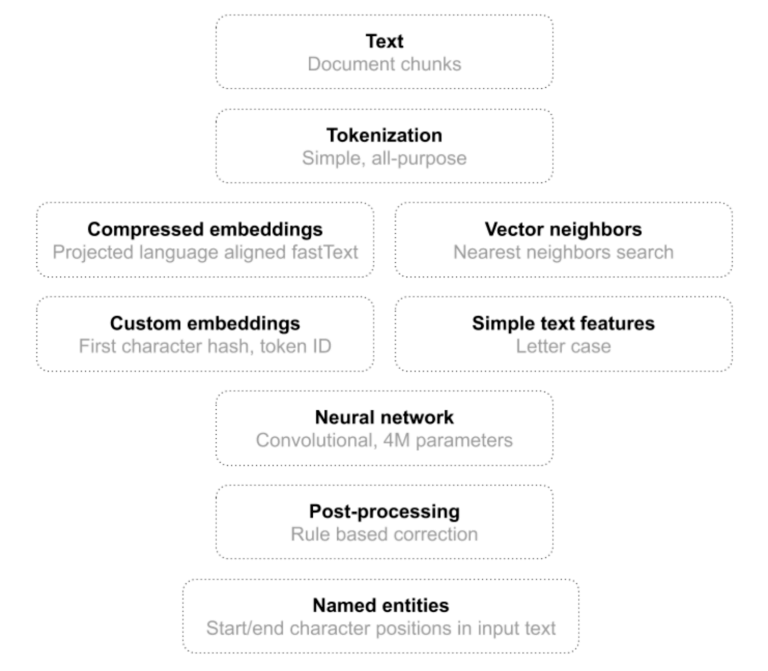
PII Tools is written in Python, and so is the model pipeline. We used Tensorflow to define and train our production model on the annotated corpus above. The pipeline uses several kinds of features to maximize accuracy.
As mentioned earlier, we used a lightweight convolutional neural network as the heart of our NER model. The model accepts a text, tokenizes it into a sequence of tokens (token positions), and spits out a sequence of name positions. A position is an offset within the original document, so we can exactly match and remediate detected names later.

Inference on a trained model.
We had a bad experience with off-the-shelf tokenizers. They usually try to be “smart” about tokenization, but fail in many cases because, in this component, there is not enough space to be smart. We had the greatest success with a simple tokenizer that recognizes 4 token groups: alphabetic sequences, whitespace, digits, and other characters. Being smarter than that always provided worse results.
Input Features
Another critical point here is how to choose token features. Features have to be fast to compute and as informative as possible. The best performance-information trade-off was achieved by combining:
- simple "letter case" features;
- precomputed language-aligned fastText vectors, projected with umap to a lower dimension;
- trained short token embedding to cover tokens not in precomputed vectors;
- trained vector embedding of the first character of a token to differentiate between token groups and to differentiate characters inside the “other” token group.
For the pretrained embedding vectors, we have to keep a dictionary of relevant tokens and their vectors, which could potentially be fairly big, consuming too much RAM. Thus, for each language, we picked a subset of:
- the most frequent tokens,
- tokens with the highest probability to be a part of a name (as calculated on the training dataset), and
- tokens with the tightest confidence interval to be a part of a name.
Furthermore, we included another set of tokens whose vectors were in a close neighborhood of the tokens identified above, and assigned them the vector of their respective neighbor. This optimization trick increased our dictionary size 2-4x depending on the language, while costing negligible extra space.
We then massaged features through a convolutional network with standard 1D convolutions and leaky ReLU activation units. By deepening the network to 10+ layers, we can achieve a reception field of 20+ tokens, which is enough for this task. This way we avoided costly LSTM, GRU, or transformer’s attention units. Outputs of the neural networks are tags indicating whether the current token is the beginning, middle part, or the end of a person's name, or a non-name token.
Post-processing
To make sure the model output is reasonable, we then apply a few lightweight post-processing steps, such as ignoring person names that do not contain any statistically strong name tokens, or where all tokens are common words. For this, we leveraged the corpus statistics again.
Such "corrected" output can be fed back into the training corpus, so that the NN model learns not to make this type of mistake again. In practice, we find that having post-processing steps is highly desirable anyway, both as a quick approximation of a retrained model and also as a fail-safe paradigm, for data patterns that CNNs have trouble picking up from a limited number of training samples.
Model minimization
If you recall, accuracy is only one of our design goals. Being practical in terms of computational speed (CPU) and memory footprint (RAM) is equally important.

The entire trained model for the four target languages takes about 70 MB on disk, and slightly more after being loaded in RAM. Parts are shared in RAM between individual scanner processes using mmap.
To compress the necessary model dictionaries and save even more RAM and CPU, we use DAWG, an excellent FSA-based storage. Our (versioned) model representation takes up roughly 70 MB on disk, which includes:
- the trained Tensorflow Lite convnet model,
- precomputed vector embeddings for 300k+ tokens, for all languages combined,
- a token dictionary, and
- the corpus token statistics.
In short, everything that's needed to run the name detection in production.
PII Tools uses parallelization for performance, so some of these data structures are shared in RAM between worker processes using mmap. This allows further memory reduction on heavy-load systems with many scan workers.
Training and optimization

NER training pipeline.
Training the whole model takes 1 to 2 days on a low-end server hardware with 8 CPUs and 1 GPU. 10 GB of training data has to be processed while applying data augmentation on-the-fly.
A few simple tricks help with dataset diversification and resulting model robustness. One is swapping letter casing – making all words lowercase, or swapping the letter case.
Another trick we found useful is to inject more information into training via multi-tasking. The neural network is not only trained on predicting token tags, but it also has to guess the language of text in the receptive field, guess how likely a computed token is inside a name, or predict tags for tokens in a close neighborhood. This acts as a regularizer for the training, and the model internalizes additional information without needing to explicitly provide it on input.
Conclusion
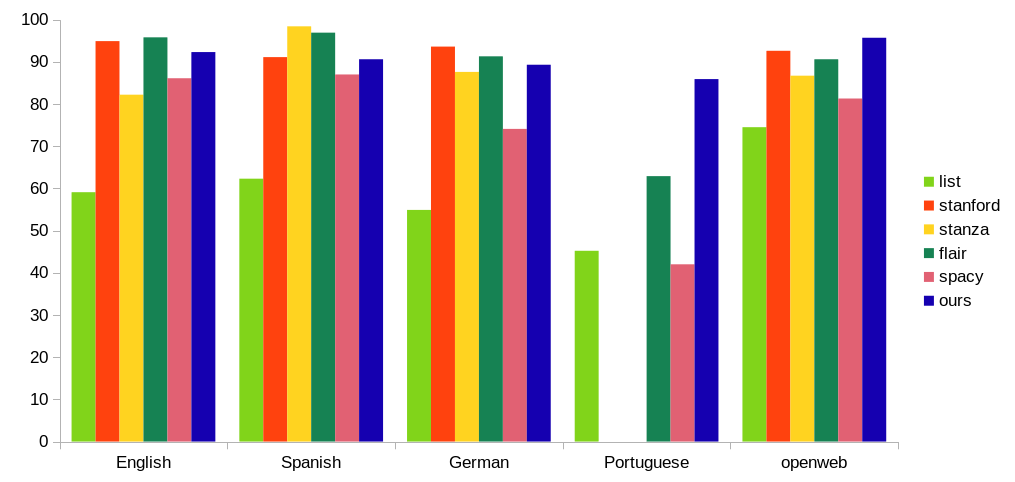
Money shot from the previous post – F1 scores for different datasets and NER solutions. Visit NER Results for more benchmarks and speed & RAM comparisons.
PII Tools is a commercial product, so while we cannot release the full source and data, I hope you at least found my tips here useful. If you'd like to see the NER model in action, alongside our other detectors for passport scans, home addresses, PII, PCI, and PHI information, contact us with your business case.
Questions? Want to see a live demo? Get in touch.
Frequently Asked Questions (FAQ)
What is the technical approach to detecting person names in text?
Modern systems use Named Entity Recognition (NER) models, often based on transformer architectures, to identify person names within unstructured text with high contextual accuracy.
How do transformer-based models improve name detection?
Transformer models (like BERT-style architectures) understand context across entire sentences, allowing them to distinguish person names from similar-looking words or entities more accurately than traditional methods.
What metrics are used to evaluate person name detection systems?
Performance is typically measured using precision, recall, and F1 score, which help evaluate how accurately a model identifies names while minimizing false positives and false negatives.
Why are hybrid systems used in PII detection pipelines?
Hybrid systems combine machine learning models with rule-based logic to improve reliability, handle edge cases, and ensure more consistent performance in production environments.
What challenges exist in scaling name detection systems?
Key challenges include processing large document volumes efficiently, maintaining low latency, handling multilingual data, and ensuring consistent accuracy across different domains.
How important is preprocessing in name detection workflows?
Preprocessing is critical because tasks like tokenization, text normalization, and noise removal significantly improve the accuracy of downstream NER models.
Can person name detection systems be customized for specific industries?
Yes. Many enterprise systems fine-tune NER models on domain-specific datasets (e.g., legal, healthcare, or finance) to improve accuracy for industry-specific terminology and naming conventions.
What is PII Tools?
PII Tools is sensitive data discovery software, so you can discover, analyze, and remediate PII across all your digital assets, on premises or on your Private Cloud. Schedule a FREE DEMO and secure your PII for good!
