



Detecting people’s names is part and parcel of PII discovery. Traditional techniques like regexp and keywords don’t work because the set of all names is too varied. How do open-source Named Entity Recognition (NER) engines compare, and can we do better?
Part 1 deals with NER results and benchmarks, while Part 2 discusses technical neural network details. Or download the free Detecting Personal Names in Texts - Whitepaper, or review the PII Tools Documentation online.
Key Takeaways
- Detecting person names in text requires context-aware AI and Named Entity Recognition (NER) because names appear in many formats that simple rules cannot reliably identify.
- Open-source NER tools often struggle with real-world documents, especially when dealing with multilingual content, OCR errors, and ambiguous names.
- Accuracy depends on balancing false positives and false negatives, making benchmarking essential when selecting a person name detection solution.
- Reliable name detection strengthens privacy and compliance efforts by improving PII discovery, document redaction, and sensitive data protection.
Modern NER Development
A quality Named Entity Recognizer (NER) is essential for detecting sensitive information like names, home addresses, passport scans, etc., for regulatory compliance and data breach management.
One option is to use a prepared list of names and surnames for this task, however, it’s obvious that such a gazetteer cannot be fully exhaustive and will ultimately fail on sentences like this:
“Calvin Klein founded Calvin Klein Company in 1968.”
Humans easily recognize what is and isn't a person's name. For machines, the task is more difficult because they have trouble understanding context. This leads to two famous types of errors:
False positives: Words detected as personal names that are not, typically because they’re capitalized ("Skin Games and Jesus Jones were one of the first western bands."), as well as
False negatives: Names missed by the detection, typically because they’re lowercase, foreign, or uncommon. (Example: "bill carpenter was playing football".)
The best way to recognize person names in text requires a tool that not only knows what names look like but can also understand the context they’re used in, together with a general domain of knowledge.
Open-Source NER Solutions
NER is a well-studied task in academia. Naturally, we turned to open-source NER solutions first. We evaluated the most popular ready-made software: Stanford NER and Stanza from Stanford University, FLAIR from Zalando Research, and spaCy from Explosion AI.
In short, none of these open-source tools were precise or fast enough for our purposes. While they work great on well-behaved data such as news articles or Wikipedia, their academic pedigree implodes when applied to the wild, messy documents of the real world.
That’s why we chose to develop our own NER, with a special focus on names as they appear in real company documents. The resulting NER is proprietary (part of PII Tools), but we decided to share some technical design tips and results here with the goal of helping others.
Part 1 of this mini-series compares our creation to popular open-source options. Additionally, we’ll benchmark a simple gazetteer-based NER that uses a predefined list of names to serve as a baseline.
| version | type | language | source | |
|---|---|---|---|---|
| list | - | list of names | multi-language | inhouse |
| stanford | 4.1 | CRF classifier | single | https://nlp.stanford.edu/software/CRF-NER.html |
| stanza | 1.1.1 | neural network | single | https://stanfordnlp.github.io/stanza/ |
| flair | 0.6.1 | neural network | multi-language | https://github.com/flairNLP/flair |
| spacy | 2.3.2 | neural network | multi-language | https://spacy.io/ |
| pii-tools | 3.8.0 | neural network | multi-language | https://pii-tools.com/ |
Our requirements for the new NER:
- Multi-language, with a special focus on English, Spanish, German and Portuguese/Brazilian;
- The ability to accept arbitrary document contexts: text coming from PDFs, Word documents, Excel, email, database field, OCR…;
- Efficiency, for processing large amounts of text quickly on a CPU (no need for specialized GPU hardware) and with a low memory footprint,
- Flexibility to evolve the model behavior: retraining, adding new languages, correcting detection errors;
- Accuracy to minimize false positives and negatives.
When comparing our NER, we evaluated performance on standard benchmark datasets, CoNLL-2002 (for Spanish), CoNLL-2003 (English, German) and LeNER-Br (Portuguese).
We also included a manually annotated openweb dataset, to ensure we were testing on data that no NER system (including ours!) has seen during training. The text for this dataset was randomly sampled from the English OpenWebTextCorpus. We value results on OpenWeb the most because it reflects the actual (messy) data found in real documents the closest (among these public datasets).
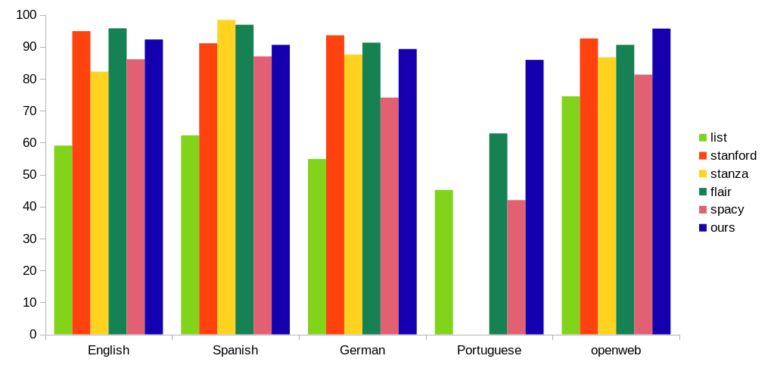
NER Accuracy
We measured F1 scores for person names detected by each software. F1 scores range from 0 to 100, the higher the better. A “hit” (true positive) means the entire name was matched exactly, beginning to end. This is the strictest metric; we specifically don’t calculate success over the number of correctly predicted tokens, or even individual characters.
| English | Spanish | German | Portuguese | openweb | |
|---|---|---|---|---|---|
| list | 59.1 | 62.3 | 54.9 | 45.2 | 74.5 |
| stanford | 94.9 | 91.1 | 93.6 | -- | 92.6 |
| stanza | 82.2 | 98.4 | 87.6 | -- | 86.7 |
| flair | 95.8 | 96.9 | 91.3 | 62.9 | 90.6 |
| spacy | 86.1 | 87.0 | 74.1 | 42.0 | 81.3 |
| pii-tools | 92.3 | 90.6 | 89.3 | 85.9 | 95.7 |
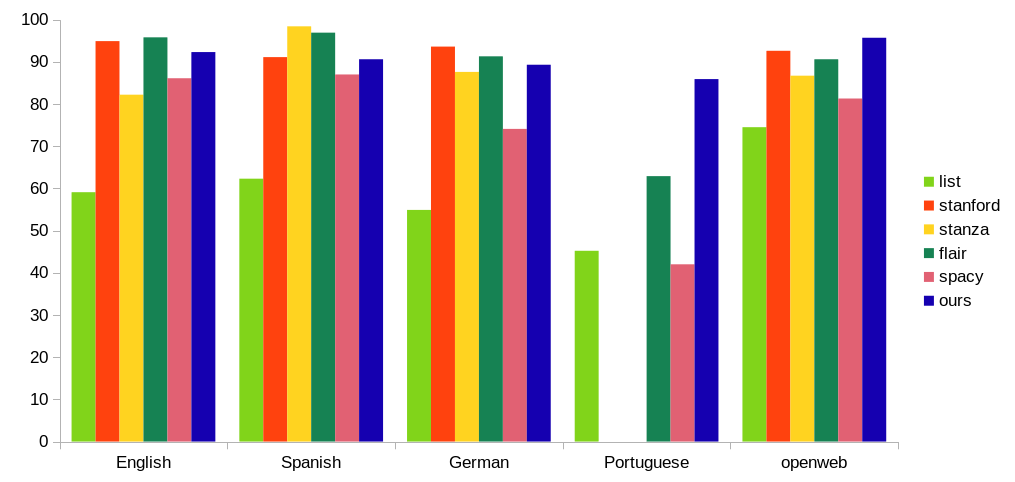
F1 scores of NER software that detect person names
In all tests, our NER is among the top contenders – but keep in mind that accuracy was just one of our 5 design goals. For example, we “lost” a few F1 points on purpose by switching from Tensorflow to TF lite, trading accuracy for a much smaller and faster model.
For Portuguese (Brazil, LGPD) and the OpenWeb dataset, PII Tools is the clear winner. As mentioned above, OpenWeb reflects “real data” the closest, making this a great success.
Let's look at some concrete examples:
| stanford | stanza | flair | spacy | pii-tools | |
|---|---|---|---|---|---|
| Calvin Klein founded Calvin Klein Company in 1968. | ok | ok | ok | ok | ok |
| Nawab Zulfikar Ali Magsi did not see Shama Parveen Magsi coming. | ok | ok | ok | fail | ok |
| bill carpenter was playing football. | fail | fail | fail | ok | ok |
| Llanfihangel Talyllyn is beautiful. | fail | fail | fail | fail | ok |
| Skin Games and Jesus Jones were one the first western bands. | fail | fail | fail | fail | fail |
Although these samples are more edge cases, they still serve great to get an idea of what detectors have to deal with and how successful they are.
NER Performance
Now, let’s look at our next requirement. Detection performance was measured on a CPU, our pii-tools NER was artificially restricted to a single process with a single thread, and others were left in their default settings.
| speed short [kB/s] | speed long [kB/s] | startup time [s] | RAM usage [MB] | |
|---|---|---|---|---|
| list | 350.0 | 1100.0 | 1.1 | 1420 |
| stanford | 30.0 | 30.0 | 1.5 | 248 |
| stanza | 0.4 | 1.2 | 6.1 | 1073 |
| flair | 0.1 | 0.1 | 5.2 | 5341 |
| spacy | 70.0 | 200.0 | 0.5 | 123 |
| pii-tools | 35.0 | 230.0 | 1.3 | 387 |
Overall, it’s clear that FLAIR and Stanza are out of the question due to their noticeably slow speeds and high RAM usage. A worthy competitor from the performance perspective is spaCy, whose creators put a great deal of effort into optimization. Unfortunately, spaCy’s tokenization quirks and opinionated architecture proved too inflexible for our needs.
Likewise, Stanford NER is the most accurate among the open-source alternatives, however, it’s quite rigid; it's quite hard to update its models or add a new language. Plus, its GNU GPL license won’t be to everyone’s liking.
Flexibility
Our focus on industry use calls for frequent model modifications: adding new languages, new kinds of documents (document contexts in which names may appear), and fixing detection errors.
To adapt the PII Tools NER model quickly, we built a pipeline that utilizes several “weaker” NERs and automatic translation tools to build a huge training corpus from varied sources. This focus on real-world data, along with a robust automated Tensorflow training pipeline, allows new languages to be added and NER outputs to be more controlled more easily than with other open-source solutions.
While developing our pii-tools NER, we implemented most components from scratch, including:
- a large-scale annotated dataset (proprietary data)
- a tokenizer (critical; none of the open-source variants does this part well)
- token features (neural network input)
- convolutional neural network (NN architecture)
- data augmentation and training pipeline (for grounded model updates)
- various tricks to push performance or to squeeze a lot of information into a smaller parameter space
Improved Sensitive Data Discovery
After our testing, we can safely say our in-house developed NER meets all the necessary requirements we put it up against. Its ability to reliably and quickly detect person names in texts sets it apart from the rest.
But you don’t have to take our word for it. You can download and review the Detecting Personal Names in Texts - Whitepaper for free or even inspect the in-depth PII Tools documentation for yourself.
Also, be sure to check out Part 2 in this mini-series, as we dive deeper into the technical details of the pii-tools NER.
Experience PII Tools’ Preferred Sensitive Data Discovery for Yourself Today!
Frequently Asked Questions (FAQ)
What is person name detection?
Person name detection is the process of automatically identifying people's names in unstructured text using artificial intelligence and Named Entity Recognition (NER) techniques.
What is Named Entity Recognition (NER)?
Named Entity Recognition (NER) is a natural language processing (NLP) technique that identifies and classifies entities such as people, organizations, locations, and dates within text.
Why is detecting person names important?
Detecting person names helps organizations locate personally identifiable information (PII), automate document redaction, support compliance requirements, and reduce data privacy risks.
Can regular expressions detect names accurately?
Regular expressions can identify simple patterns but generally perform poorly for person name detection because names vary widely across languages, cultures, and contexts.
What challenges make person name detection difficult?
Common challenges include ambiguous names, multilingual content, OCR errors, unusual formatting, and distinguishing people from organizations or product names.
Are open-source NER models accurate enough for production use?
Many open-source NER models provide good baseline performance, but organizations often need additional training, benchmarking, or specialized tools to achieve high accuracy on real-world data.
How does person name detection help with GDPR and other privacy regulations?
Accurate name detection enables organizations to discover and protect sensitive personal data, making it easier to comply with regulations such as GDPR, HIPAA, and other data privacy laws.
What is PII Tools?
PII Tools is sensitive data discovery software, so you can discover, analyze, and remediate PII across all your digital assets, on premises or on your Private Cloud. Schedule a FREE DEMO and secure your PII for good!
