



The recent wave of privacy legislations around the world introduced new challenges to experts in litigation support, incident response and auditing. How can modern automation help with reliable PII discovery across emails, files, and databases?
3 Reasons Keywords Fail
Traditional approaches based on manually defined keywords and regular expressions fail for three fundamental reasons:
- High cost. Keywords and regexps are difficult to define and maintain, yet come back with a lot of errors. False positives (returned PII that's not really PII) and False negatives (real PII that was missed) undermine user trust and require additional manual reviews – hard to say which is more expensive!
- Failure to capture so-called open set categories, which include people's full names, home addresses or profile photos. How would you even begin to construct keywords or regexps to catch all names? There's no way, even in theory, to capture these critical PII types with a fixed ruleset.
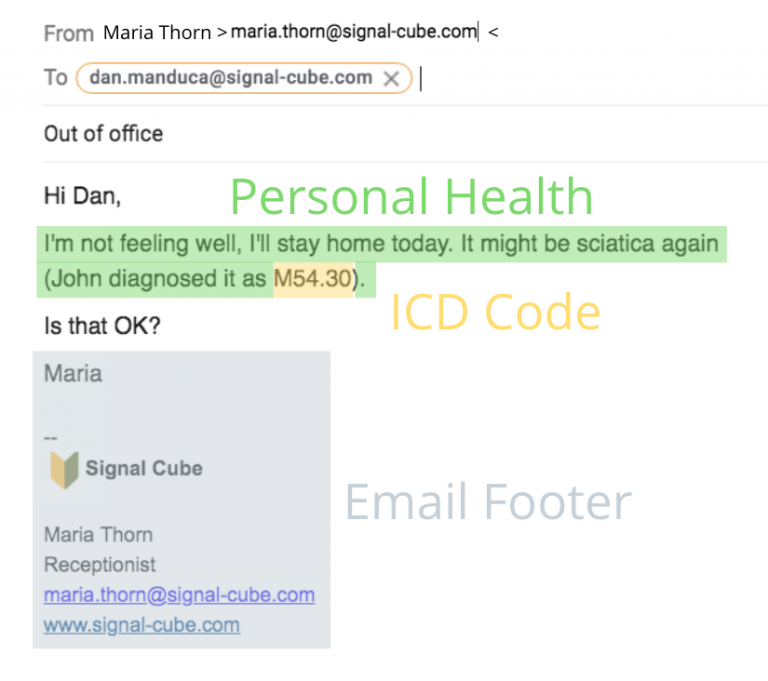
- Conceptual PII. New regulations bring new requirements on what constitutes personal and protected information. What if people discuss their sexual orientation or medical problems “in prose”, without any technical jargon?
This is sensitive information of the highest severity, yet no set of keywords can help. The overall document context, the relationships between "who says what", is absolutely critical.
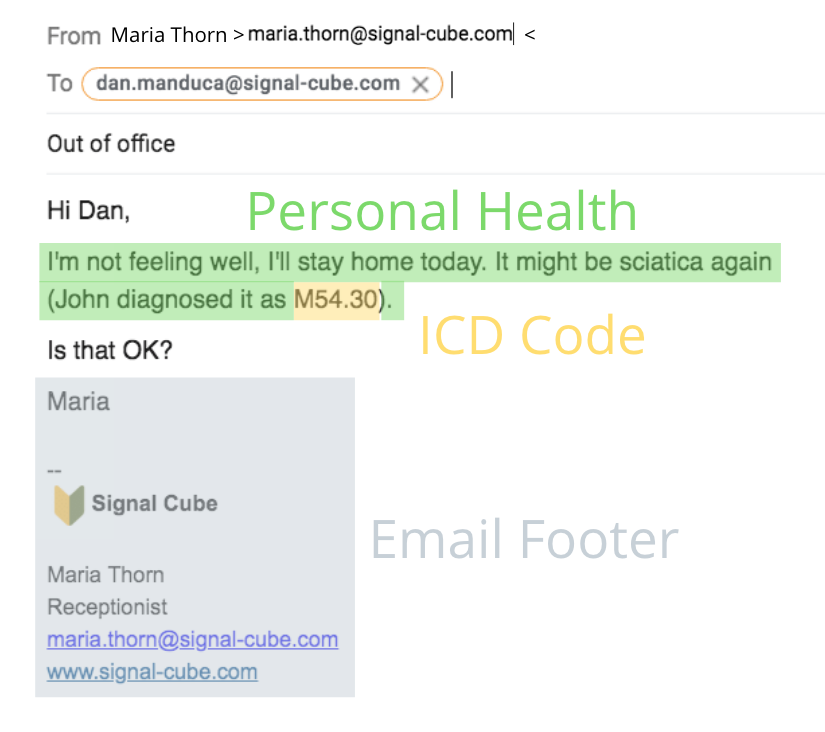
Conceptual PII goes beyond keywords and regular expressions. It requires detecting personal and sensitive data in free-form discussions, relying on natural language context.
Contextual AI to the Rescue
Machine learning brings a principled way to detect PII in context, including for images, scans and prose. The same sequence of characters may or may not be sensitive depending on its context: Is this a natural person talking about their health issues, or simply some song lyrics (no PII)? What's the document structure? The context matters.
My favourite example is "Sexual Healing" by Marvin Gaye. This is obviously not personally identifiable information, but there's no way to determine that without intelligent contextual analysis. Most legacy systems will fail miserably on such inputs (if they attempt discovery of sex-related documents at all).
| PII Ability | Rule-based systems | AI-based systems |
|---|---|---|
| detection precision | 😐 | 😊 |
| detection recall | 🙁 | 😊 |
| can detect open-set PII types (names, addresses…) |
❌ | ✅ |
| can detect conceptual PII (political views, sexual preferences, health…) |
❌ | ✅ |
| can process non-textual data (profile photos, passport scans, audio…) |
❌ | ✅ |
| can learn from new data | ❌ | ✅ |
| allows custom validators and checksums | ✅ | ✅ |
| requires expertise to develop | medium | high |
Machine learning brings a significant advantage across the board, but requires greater upfront R&D expertise to set up and deploy. This expertise is expensive, but as with most technologies, can be licensed from specialized providers without compromising your core business competency.
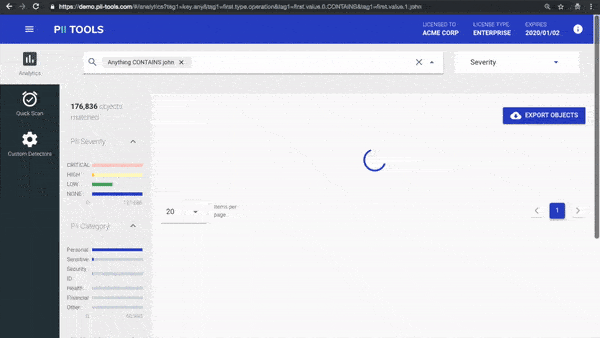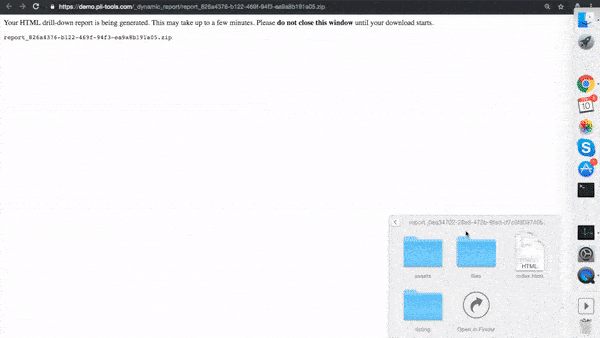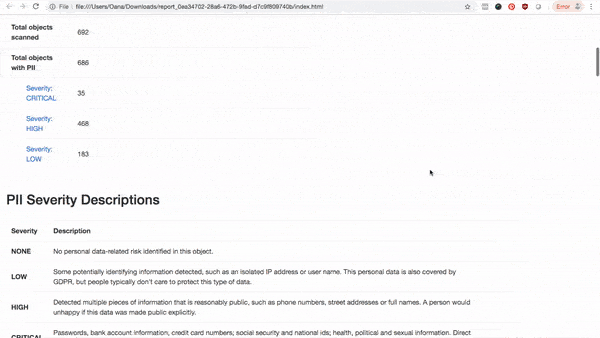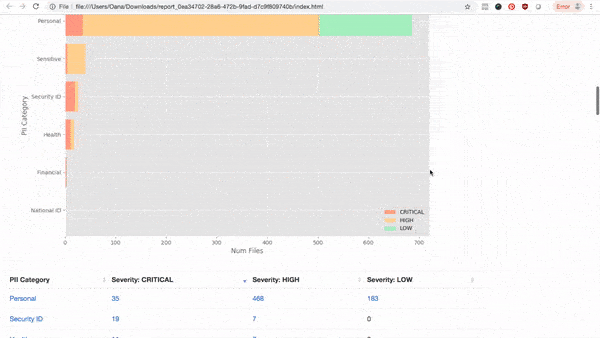
With AI-driven detections, modern PII analytics dashboard and dynamic drill-down reports, PII Tools offers unparalleled accuracy and ease of use.
